例6.2若要进行向量运算:D=A×(B+C),假设向量长度≤64,且B和C已由存储器取至V0和V1,则下面3条向量指令就可完成上述运算:
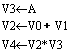
第一、二条指令因既无向量寄后器使用冲突,也无功能部件使用冲突,所以这两条指令可并行执行。第三条指令与第一、二条指令均存在先写后读的相关冲突,因而可将第三条指令与第一、二条指令链接执行,如图6.17
所示。
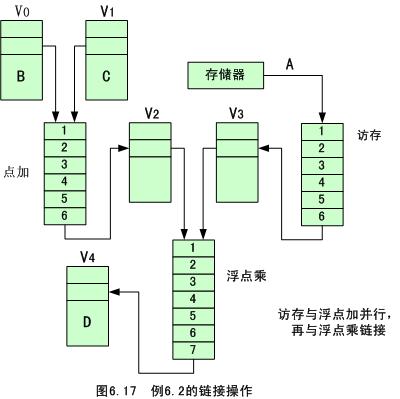
由于同步的要求,数据进入和流出每个功能部件,包括访存都需要1拍时间。
假设向量长度为N,若这三条指令全部用串行方法,则执行时间为:
[(1+6+1)+N-1]+[(1+6+1)+N-1]+[(1+7+1)+N-1]=3N+22拍
若前两条指令并行执行,第三条指令串行执行,则执行时间为:
[(1+6+1)+N-1]+[(1+7+1)+N-1]=2N+15拍
若采用链接技术,则执行时间为:
(1+6+1)+(1+7+1)+(N-1)=17+N-1=N+16拍
实现链接除了无向量寄存器使用冲突和无功能部件使用冲突外,还有时间上的要求,只有当前一条指令的第一个结果分量送入结果向量寄存器的那一个时钟周期方可链接,若错过该时刻就不能进行链接,只有当前一条向量指令全部执行完毕,释放向量寄存器资源后才能执行后面指令。另外,当一条向量指令的两个源操作数分别是两条先行指令的结果寄存器时,要求先行的两条指令产生运算结果的时间必须相等,即要求有关功能部件的延迟时间相等,如例中的访存和浮点加功能部件延时均为6拍。此外还要求这两条向量指令的向量长度必须相等,否则也不能链接。