组相联映象方式的地址变换过程如图3.35所示。在程序执行过程中,当要访问Cache时,用主存地址中的组号G按地址访问块表存储器。从块表存储器中读出来的不仅仅是一个字,而是一组字,字的个数等于组内的块数Gb。把这些字中的区号和块号与主存地址中相应的区号E和块号B进行相联比较。如果发现有相等的,表示要访问的数据已经装到Cache中了,这种情况称为Cache命中。这时,只要把同一个存储单元中的Cache块号b读出来,并且把它与主存地址中直接送过来的组号g和块内地址w直接拼接起来,就得到Cache地址。用这个Cache地址去访问Cache,把读出的一个字送往CPU。如果在相联比较中没有发现相等的,表示要访问的那个块还没有装到Cache中,这种情况称为Cache没有命中,或称为Cache失效。这时,要用主存地址去访问主存储器,把从主存储器中读出来的一个字送往CPU。同时,把包括被访问字在内的一块都从主存中读出来装入到Cache中。另外,还要修改块表存储器等。
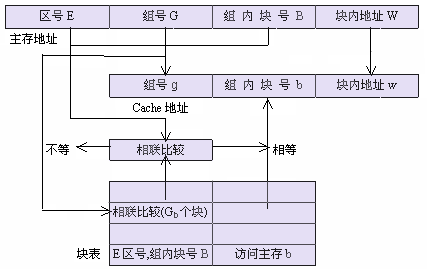
图3.35 组相联映象方式的地址变换
有效位的使用和管理方法与直接映象方式中的地址变换过程完全相同,在图3.35中没有给出来。
为了提高Cache的访问速度,可以把Cache的地址变换与访问Cache并行进行,并采用流水线方式工作。
在组相联映象方式中,组内的块数一般是很小的,如4块左右。因此,可以采用把块表存储器中一个相联比较的组按块方向展开存放,如图3.36所示。这样,可以用多个相等比较器来代替相联访问,以加块查表的速度。许多实用的组相联Cache都采用这种方法,它的地址变换过程与上面的方法类似。
另外,块表中的有效位是用来标记一个块的映象关系是否成立的。它使用和管理方法与直接映象方式中的地址变换过程完全相同。
当一个块内的字数不多时,可以把块表与Cache合并成一个存储器。图3.36中的块号b字段用Cache中的数据字来代替,并且用Cache地址中块内地址部分控制一个多路选择器,从读出的多个数据字中选择一个所需要的数据字。
组相联映象方式与直接映象方式相比,最明显的优点是块的冲突概率大大降低。例如,在直接映象方式中,主存中的一块只能映象到Cache中的一个确定块中。在每组为4块的组相联映象方式中,主存中的一块能够映象到Cache的4个确定的块中。因此,采用组相联映象方式,Cache的块失效率能够明显降低。但是,由于组相联映象方式在组内部需要进行相联比较,因此,实现的难度和造价要比直接映象方式高。
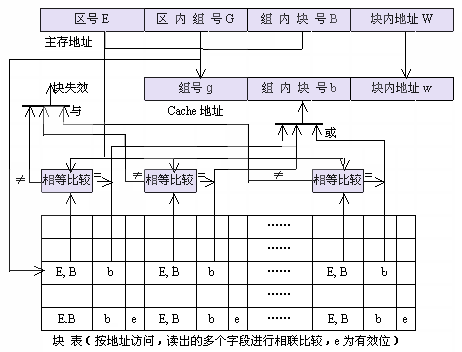
图3.36 组相联地址变换的一种实现方法
组相联映象方式与全相联映象方式相比,实现起来要容易得多,但Cache的命中率与全相联映象方式很接近。因此,组相联映象方式在许多机器中得到广泛的应用。
在组相联映象方式中,当每组的块数Gb为1时,就成了直接映象方式。同样,当每组的块数Gb与Cache的块数Cb相等时,就成了全相联映象方式。因此,直接相联映象方式和全相联映象方式是组相联映象方式的两个极端情况。
在Cache的容量和每块的大小确定之后,可以通过选择每组的块数Gb和Cache的组数Cg,即分配Cache地址中组号g和组内块号b两个字段的长度,来优化Cache的性能。主要包括块冲突概率,块的失效率,查表的速度,实现的复杂性和成本等。一般来说,每组的块数Gb越大,块的冲突概率和Cache的失效率就越低,但由于映象关系复杂,查表的速度就越慢,实现的成本也越越高。
表3.3给出了采用组相联映象方式的一些典型机器的Cache分组情况。从表中可以看出,每组的块数一般都很小。有近一半的机器选择每组为两块,最多的为16块,其主要原因是:当每个组的块数增大时,需要进行相联访问的存储器的容量将增加,造成查表的速度降低,实现成本增加。但是,当每个组的块数太少时,块的冲突概率和Cache的失效率就会增大。例如,当每组的块数为2时,主存的各个分区中相对块号相同那些块只能映象到Cache的两个特定块中,当这些块中有两个以上是当前的常用块时,就会出现所谓的颠簸现象。
表3.3 采用组相联映象方式的典型机器的Cache分组情况
|
机器型号
|
Cache的块数Cb
|
每组的块数Gb
|
Cache组数Cg
|
|
DEC VAX-11/780
|
1024
|
2
|
512
|
|
Amdahl 470/V6
|
512
|
2
|
256
|
|
Intel i860 D-Cache
|
256
|
2
|
128
|
|
Honeywell 66/60
|
512
|
4
|
128
|
|
Amdahl 470/V7
|
2048
|
4
|
512
|
|
IBM 370/168
|
1024
|
8
|
128
|
|
IBM3033
|
1024
|
16
|
64
|
|
Motolola 88110 I-Cache
|
256
|
2
|
128
|