1.直接数据挖掘:
给出所有已知的因素和输入变量,便于数据挖掘引擎根据数据模型的规则,找出各个属性之间最合理的关系。直接数据挖掘以预测未知值或目标变量为基础,即直接数据挖掘是基于已知的输入变量值预测未知数据的最大可能的取值。
直接数据挖掘采用当今流行的数据挖掘技术和算法,如决策树算法。它根据数据的分类直接求出目标值。如银行预测可能拖欠贷款的帐户,商店预测商品的销售对象等。2. 间接数据挖掘:
间接数据挖掘不用于预测,不受目标值的限制和约束。它只对数据进行整理,发掘整个数据集合的结构和数据组织形式,进行理解和应用。
例如,通过整理图书的借阅历史,可以发现喜欢读某类图书的读者有哪些共同的特点。例如,可能会发现喜欢读琼瑶小说的读者主要是年轻的女孩子。
采用聚类是对历史数据进行数据挖掘中常用的一种算法。可以先提取聚类,再利用决策树算法,对感兴趣的数据集合进行直接数据挖掘。
下面给出显示输出的示例。
图9-10
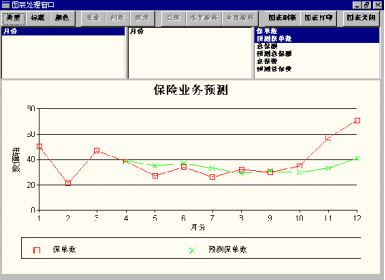 |
图9-11
 |
图9-12
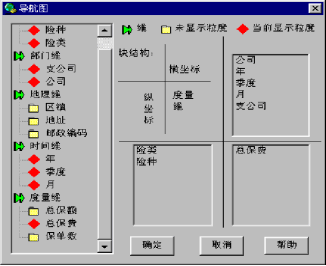 |
图9-13
 |