��数据库中某独立部分称为一个数据单元,一个数据单元小到可以是一个数据项、一个元组、一个关系,大到一个存储域,直至一个数据库。
��封锁单元的大小称为封锁粒度(Granularity)。封锁单元可以是逻辑单元,也可以是物理单元。关系数据库中的逻辑单元为:属性、元组、关系、索引直至整个数据库。物理单元为:页(数据页或索引页)、块。
��封锁的粒度、系统的并发度和并发控制的开销密切相关。封锁的粒度越大,数据库所能够封锁的数据单元就越少,系统开销也越小,并行度也就越低。反之,封锁粒度越小,并行度越高,系统管理锁的开销也越大,实现起来也更加困难。因此,在封锁单元的大小、并行度和管理锁的开销之间要进行权衡。
��因此,如果在一个DBMS系统中同时支持多种封锁粒度供不同的事务选择是比较理想的,这种封锁方法称为多粒度锁(Multiple Granularity Locking)。选择封锁粒度应同时考虑封锁开销和并发度两个因素,适当选择封锁粒度以求得到最优的效果。
��一般情况下,需要处理大量元组的事务可以用关系作为封锁粒度;需要处理多个关系的大量元组的事务可以以数据库为封锁粒度;对于一个处理少量元组的用户事务,以元组作为封锁粒度就可以了。
(1)多粒度锁
图7-12
|
|
��多粒度锁的封锁策略允许多粒度树每个节点被独立的加锁。对一个节点加锁意味着这个节点的所有子节点也被加以同样类型的锁。因此,在多粒度锁中一个数据对象可能被显式封锁和隐式封锁。
��显式封锁是应事务的要求直接加到数据对象上的封锁;隐式封锁是该数据对象没有独立加锁,是由于其上级节点加锁,因此本节点也被加上了锁。但是在多粒度封锁中,这两种加锁的效果是一样的。例如,在图7-12中,事务T要对关系R1加独占锁,系统必须搜索其上级节点数据库、关系R1以及R1中的每一个元组;如果其中一个数据对象已经上了不相容的锁(独占锁,共享锁),则T必须等待这些不相容的锁被释放之后才能再加锁。
��一般情况下,在对某个数据对象加锁过程中,系统要检查该数据对象上有无显式封锁与之冲突;还要检查其所有上级节点,看本事务的显式封锁是否与该数据对象上的隐式封锁有冲突;还要检查其所有下级节点,看本事务的显式封锁是否与下级节点的显式或隐式封锁有冲突。显然这种检查方法效率很低,为此人们引入了意向锁(Intention Lock)。 (2)意向锁(I锁,Intention Lock)
��顾名思义,意向锁是在加锁节点的祖先上用作"意向"或"标记"。意味着锁是加在该节点的下属节点上。设置意向锁是避免对加锁节点祖先进行显式或隐式的加锁请求,减少了结点和它的祖先之间加锁的不相容性。
��引入意向锁I(Intend),当为某节点加上I锁,表明其某些内层节点已发生事实上的封锁,防止其它事务再去显式封锁该节点。
��I锁的实施是从封锁层次的根开始,依次占据路径上的所有节点,直至要真正进行显式封锁的节点的父节点为止。
意向锁分为意向读IR(Intention Read)、意向写IW(Intention Write)和读意向写(Read Intention Write)三种。 ��
使用多粒度锁,一个数据库中的对象可以按层次组织,在关系数据库中,节点可以是数据库、关系表或元组。为了锁住一个下级粒度对象,事务必须用一种较弱的加锁方式首先锁住它的上级祖先对象。其目的是把对细小粒度加锁的影响用一种适当的意向锁传播到大粒度。这样,在对一个元组上设置读锁之前,事务必须先对该关系表设置一个意向读IR(Intention Read)锁。类似的,事务在一个元组上设置写锁之前,必须先对该关系表设置一个意向写IW(Intention Write)锁。有时候,一个事务可能想读一个关系表的多个元组,而修改其中的少数元组,这时可以在该关系表上建立一个读意向写(RIW)锁。一个表上的RIW锁隐含着对该表的所有元组设置了读锁,不必再为单个元组施加读锁,而在要修改的元组上设置写锁来实现。
��在多粒度锁模式中,可使用一个矩阵设置不同类型的锁,如图7-13所示。
图7-13 多粒度锁相容矩阵
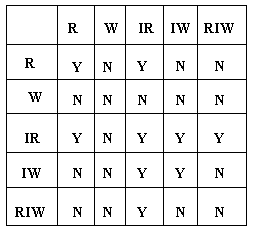
|
��沿着层次结构加锁在许多情况下是很有用的。例如,在修改关系模式时,为了增加一个新属性,该表中现有元组也必须被修改,以使新定义的属性有存储空间。