在SQL Server中,可以用企业管理器或用SQL语句完成索引的创建。
(1) 使用企业管理器创建索引:
在设计表格的时候,选择列的快捷菜单"属性",切换到"属性"页对表格的索引进行添加。如图4-19,在表student1为列sno中添加簇集索引IX_TABLE1。
图4-19
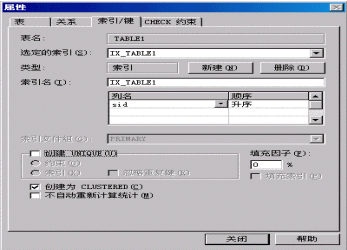 |
(2) 使用SQL语句创建索引
语法格式如下:
CREATE [UNIQUE] [CLUSTER|NONCLUSTERED] INDEX index_name
ON table_name(column_name[ASC/DISC]
[,column_name[ASC/DISC]]….])
参数说明:
UNIQUE:表示创建的索引是唯一索引,每个索引只对应一个元组值。
CLUSTERED:表示创建的索引是簇集索引。
NONCLUSTERED:表示创建的索引是非簇集索引。
Index_name:创建的索引名。
Table_name:创建索引所在的表名。
Column_name:创建索引使用的列名。由ntext、text或image数据类型组成的列不能指定为索引列。
ASC|DESC:确定具体某个索引列的升序或降序排列。默认设置为ASC。
| 例1,为TEACHER表建立唯一索引tnamex,升序排列。不管教师是否有重名,每个索引值只对应一个教师名字。 CREATE UNIQUE INDEX tnamex ON TEACHER(tname) |
|
例2,在SC表上按学号sno建立聚集索引scinx。 CREATE CLUSTER INDEX scinx ON SC(sno) 在选课表中建立聚集索引scinx之后,同一个学生的所有选课成绩记录物理地排在一起。所以,查询某个学生的学习成绩或打印某个学生的成绩单速度就比较快。如表4-3。 |
表4-3
CREATE NONCLUSTERED INDEX stu_index ON student(sname) |
(3) 在两个或更多属性上建立索引:
假如查询经常涉及到多个列值的检索条件,可在一个关系表上建立多个属性的索引,提高查询效率。否则会降低查询效率。
例如,选课关系sc,主码(sno, cno),经常查询某学号的同学选修某课程的成绩。为两个属性建立索引的语句如下:
CREATE INDEX Scidx ON sc(sno, cno);
(4) 使用索引的原则:
要不要建索引以及如何建索引,当属于内模式的概念,这是数据库设计中一个很重要的问题。设计人员要仔细考虑实际应用中修改与查询的频率,权衡建索引的利弊。例如,若一关系的经常性操作是数据的修改,则不宜建索引。但有些修改语句可能包含着查询操作。
一般来说,建索引有几项参考原则:
● 值得建索引:记录有一定规模,而查询只局限于少数记录。
● 索引用得上:索引列在where子句中应频繁使用。先装数据,后建索引:对于大多数基本表,总是有一批初始数据需要装入。该原则是说,建立关系后,先将这些初始数据装入基表,然后再建索引,这样可加快初始数据的录入。如果建表时就建索引,那么在输入初始数据时,每插入一个记录都要维护一次索引。当然,索引早建晚建都是允许的。
● 在下列三种情况下,有必要建立簇索引:
(1)查询语句中采用该字段作为排序列
例如,我们经常执行下列语句:
SELECT * FROM authors ORDER BY au_id
这时候有必要考虑在该表格上建立以au_id为关键字的簇索引。
CRATE CLUSTERED INDEX au_index On authors (au_id)
(2)需要返回局部范围的大量数据
例如,我们要做如下的查询:
SELECT * FROM authors
WHERE zip BETWEEN 94618 AND 96214
这时就有必要在zip列上建立簇索引。
CRATE CLUSTERED INDEX zip_index On authors (zip)
SELECT * FROM student,dept
WHERE student.dno=dept.dno
对以上情况,建立簇索引会提高访问数据库的效率。建立簇索引的语句如下:
CRATE CLUSTERED INDEX dept_index On student(dep_id)
注意:当在同一表格中建立簇索引和非簇索引时,先建立簇索引后建非簇索引比较好。因为如先建非簇索引的话,当建立簇索引时,SQL Server会自动将非簇索引删除,然后重新建立非簇索引。每个表仅可以有一个簇索引,最多可以有249个非簇索引。它们均允许以一个或多个字段作为索引关键字(Index Key),但最多只能有16个字段。
SQL Server只对那些能加快数据查询速度的索引才能被选用。如果利用索引检索还不如顺序扫描速度快,SQL Server仍用扫描方法检索数据。建立不能被采用的索引只会增加系统的负担,降低检索速度。因此,可利用性是建立索引的首要条件。