|
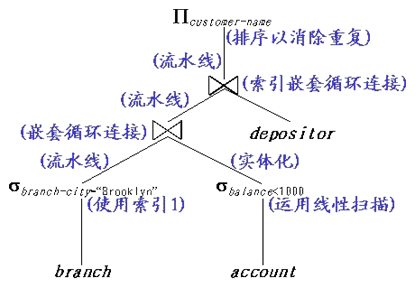
图9-6-1:一个查询执行计划的例子
|
| 1、查询优化器的优化方法 ��总之,查询优化器在第二步的主要工作是: ��⑴�选择实现关系运算的具体算法(包括各种索引,因为算法是和索引密切相关的); ��⑵�协调各关系运算的具体执行,例如,是采用实体化计算方法还是采用流水线计算方法; ��⑶�对整个关系代数表达式进行优化,产生代价最小的查询执行计划。 ��一般来说,简单地为每个关系运算选择一个代价最小的算法,整个表达式的代价也可能最小。但这样做往往是事与愿违(例如,索引嵌套循环连接并不是实现连接运算代价最小的算法,但是它可以提供把结果流水地传给下一个运算的机会)!因此,必须采用一定的查询优化策略才能满足需要。查询优化方法包括:基于代价的优化和启发式优化。 2、基于代价的优化方法 ��基于代价的优化,其核心思想是将各种可能的查询执行计划全部产生出来,然后从中估计出代价最小的一个。这件事情说起来容易做起来很难,而且几乎是不可能的!例如,考虑r1��r2��r3的连接顺序的可能组合就有12种之多!如图9-6-2所示: |
|
图9-6-2:r1��r2��r3的各种连接顺序

|
| ��如果估计每一种连接顺序的代价,则将会花费很长的时间。也有可能在运算代价还没有估计完之前,没有优化的连接运算r1��r2��r3的计算结果已经出来了!因此基于代价的优化方法在某些时候优化本身的代价太高,有点得不偿失 |
 
|
| 3、启发式优化方法 ��由于基于代价的优化方法本身的代价太高,因此在很多系统中采用启发式规则来减少基于代价优化的可选方案数。这种摸着石头过河的优化方法就叫启发式优化方法。启发式优化的规则如下: ��⑴�将合取(∧)选择运算分解为单个选择运算序列; ��⑵�尽可能早地执行选择运算; ��⑶�确定哪些选择运算和连接运算将产生比较小的关系,重新组织表达式中多个连接的顺序; ��⑷�将其后跟有选择运算的笛卡尔积运算替换成连接运算; ��⑸�将投影属性加以分解,并尽可能早地执行投影运算; ��⑹�识别哪些运算可用流水线计算方法执行就采用流水线计算方法。 |
 |
| � |