|
1、嵌套循环连接 |
|
图9-4-2:嵌套循环连接算法的说明
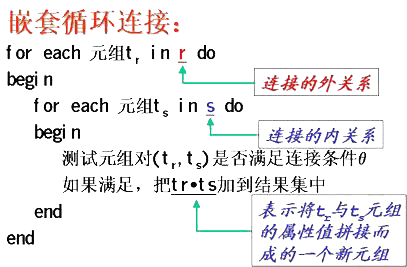
|
| ��如图9-4-2所示该算法分析如下: ��⑴�与文件的线性扫描算法类似,关系文件的每个数据块都必须访问; ��⑵�不要求有任何索引,任何连接条件都能适应; ��⑶�对于关系r的每一条记录必须对s做一次完整的扫描,因此算法的代价为: ����①�最坏情况下,缓冲区只能容纳每个关系的一个数据块,因而 ������EJ = nr * bs + br ����②�最好情况下,两个关系都能放到内存里,因而算法代价为 ������EJ = bs + br 2、索引嵌套循环连接 ��与嵌套循环连接算法的代码相同,只不过将算法中的文件扫描策略用索引扫描策略代替。算法代码如下: for each 元组tr in r do begin ��for each 元组ts in s do ��begin ����测试元组对(tr,ts)是否满足连接条件θ ����如果满足,把tr・ts加到结果集中 ��end end |
|
图9-4-3:索引嵌套循环连接算法的说明

|
| ��如图9-4-3所示,在给定元组tr的情况下,在关系s中查找满足连接条件的元组本质上是在s上做选择运算。因此该算法的代价为: ���EJ = br + nr * c 其中c是使用连接条件并利用索引对关系s进行单个选择运算的代价。 |