| ��1、问题的提出 ��假设我们有如图7-3-4所示的两个关系customer和depositor,对于它们的自然连接运算,用SQL表达如下: select customer-name, … from customer, depositor where customer.customer-name = depositor.customer-name |
|
图7-3-4关系customer和depositor
.gif) .gif)
|
| 那么如何在文件中组织记录,才能提高上述自然连接的效率呢? ��2、问题的解决 ��由于自然连接运算需要不断地访问磁盘文件中的记录,使得自然连接的性能瓶颈出现在磁盘I/O上。因此可以考虑把相关记录放在磁盘上一个块(或临近的块)中存储,这样一次读块操作就能取得需要连接的所有相关记录,减少了磁盘I/O次数,提高了连接的性能。具体做法是将关系customer和depositor在文件中按图7-3-5所示的方式进行组织。 |
|
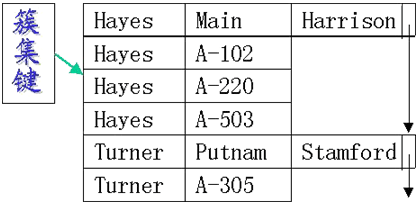
图7-3-5簇集文件组织示例
|
| 从图中我们可以看出,簇集文件组织就是把有关的记录按簇集键值集中在一个物理块内或物理上相邻的区域内,以提高某些数据访问的速度。在这个例子中,簇集键就是自然连接的连接属性。一般来说,簇集键是用户用来集中存储记录所依据的某个属性或属性集。简单地说,簇集键是某个属性或属性集,根据它们的值来确定记录的集中存放。在实际的DBMS中,簇集的建立是使用create
cluster语句。 ��3、簇集文件的问题 ��虽然簇集文件组织能够为某些数据查询带来巨大的好处,但是簇集文件组织也还存在下列问题:⑴如果改用其他属性或属性集做簇集键,将引起所有记录的移动;⑵如果一个记录的簇集键值修改了,则这个记录也要做相应的移动;⑶如果不是针对簇集设计的查询,而是按其他条件进行查询,则这种簇集没有一点好处! ��4、何时才考虑使用簇集 ��虽然簇集能够为某些查询带来巨大的好处,使得查询性能显著提高,但是在实际应用中还是要慎用簇集。只有在下列情况下,才可以考虑使用簇集: ��⑴�通过簇集键进行访问或连接是该表的主要应用,与簇集键无关的其他访问很少,或是次要的。尤其当语句中包含与簇集键有关的ORDER BY、GROUP BY、UNION、DISTINCT等语法成分时,簇集格外有用,可以省去对结果的排序等工作; ��⑵�对应每个簇集键值的平均记录数既不太少,也不太多。太少了则簇集的效益不明显,甚至浪费物理块的空间;太大了就要采用多个溢出块,同样对提高性能不利; ��⑶�簇集键的值应相对稳定,以减少因修改簇集键值而引起的巨大的维护开销。 �� |