|
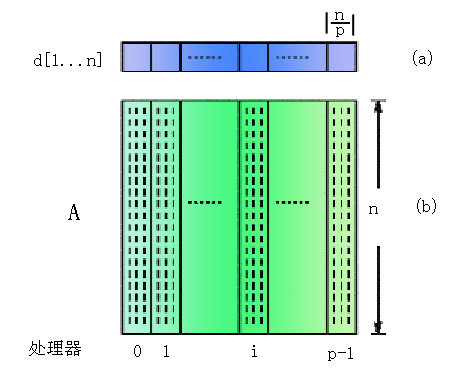
图6.6.5 矩阵A和最短路向量d在各个处理器的分布
设处理器个数为p,图G中共有n个结点,采用邻接矩阵的存储方式存储于矩阵A中。对矩阵A进行列方向的条带状划分,使得每个处理器上存储n/p列,参见图6.6.5。最短路向量d也按照各个元素对应的结点分布到相应的处理器上。
对于每次迭代,各个处理器上所进行的计算主要是求最小值和更新向量d,这需要消耗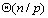 的时间。每次迭代中求最短边需要各个处理器之间的通信,并且新插入的最小树中的结点u也要通知给所有的处理器,这就需要一个全局求极值的通信过程和一个一到多广播的通信过程。 的时间。每次迭代中求最短边需要各个处理器之间的通信,并且新插入的最小树中的结点u也要通知给所有的处理器,这就需要一个全局求极值的通信过程和一个一到多广播的通信过程。
对于超立方体互联结构,求全局极值和一到多广播所需要的通信时间都是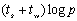 ,这样n次迭代总的时间(包括计算时间和通信时间)为: ,这样n次迭代总的时间(包括计算时间和通信时间)为:

由于串行处理时间为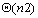 ,因此加速比为: ,因此加速比为:
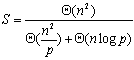
效率为:
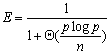
算法的成本为:
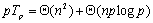
对于二维网格互联结构,求全局极值和一对多通信需要的时间都是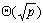 ,因此n次迭代总的时间(包括计算时间和通信时间)为: ,因此n次迭代总的时间(包括计算时间和通信时间)为:
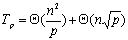
由于串行处理时间为 ,因此加速比为:
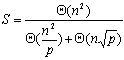
效率为:
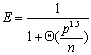
算法的成本为:
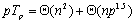
|