|
Cannon乘法的矩阵分块方式与简单分块矩阵法完全一样,但它没有等到所有的块Aik与Bkj(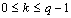 )都存储到本机后才进行Cij的计算,而是每拿到一个Aik和Bkj就进行乘法计算,小块计算完毕后就可以腾出空间给别的矩阵块使用。 )都存储到本机后才进行Cij的计算,而是每拿到一个Aik和Bkj就进行乘法计算,小块计算完毕后就可以腾出空间给别的矩阵块使用。
算法的分为准备阶段和循环阶段,在准备阶段,块Aij向左循环移动i步,Bij向上循环移动j步。在循环阶段的每个循环中,处理器Pij计算它上面两个当前块Aij和Bij的乘积,然后将Aij向左循环移动一步,Bij向上循环移动一步。所谓循环移动一步,就是移动一步之后取模,与算术移动相对应(可以联想到汇编语言中的循环移位)。
图6.3.12演示了在16个处理器上完成两个4×4矩阵A和B相乘的过程。在准备阶段,矩阵A的第0行(A00到A03)不动,即向左移动0步;A10至A13向左循环移动一位;A20至A23向左循环移动2位;A30至A33向左循环移动3位。矩阵B的第0列(B00到B30)向上移动0位;B01至B31向上循环移动一位;B02至B32向上循环移动2位;B03至B33向上循环移动3位。在循环阶段,每计算一次块矩阵的乘法就把用过的块矩阵A移动给左邻居,把块矩阵B移动给上邻居。
Cannon算法的性能分析可以参照简单分块矩阵法给出,在此省略。
|