|
一下只讨论块棋盘划分和映射的情况,循环棋盘划分和映射的情况类似。
还是从最极端的情况p=n2开始,见图6.3.9。此时每个处理器存放矩阵的一个元素,最初某些(n个)处理器中存放有向量的一个元素。设向量X的元素Xi存放在处理器Pii中,如果不是这样,则本行的某处理器通过一对一通信将向量元素传送到Pii。然后处理器Pii需要把元素Xi传送给本列的其它处理器,这样每个处理器就都可以进行并行地进行元素相乘了。元素相乘的结果再按照行累加起来,并交给每行的一个处理器。
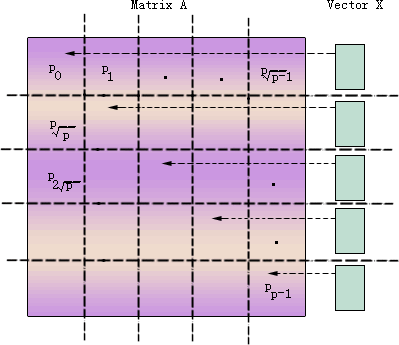
(a) 初始划分和通信;
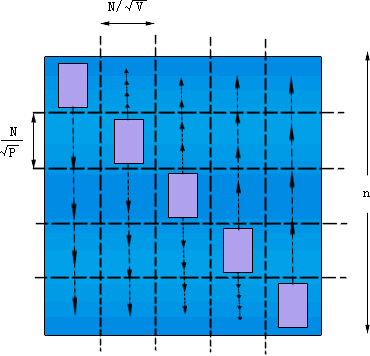
(b) 沿着列方向传送元素;
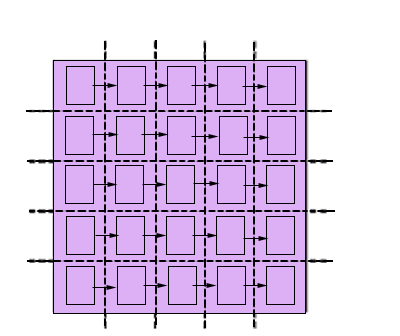
(c) 元素相乘和结果按行累加
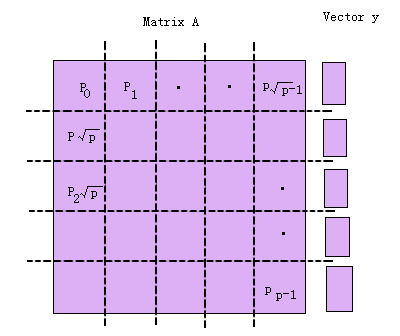
(d) 结果向量的分布
图6.3.9 并行矩阵向量乘法(p=n2;块棋盘划分)
处理器个数p<n2的情况与上述过程非常类似。下面只分析二维网格互联和切通路由(Cut-Through
Routing)情况下的时间性能。
参照图6.3.9来说明问题。首先,步骤(a)所花费的通信时间为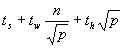 ;步骤(b)的时间为 ;步骤(b)的时间为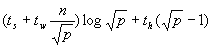 ;步骤(c)的通信时间为 ;步骤(c)的通信时间为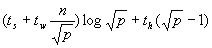 ,乘法计算时间为n2/p。将这几项相加,总的时间大约是: ,乘法计算时间为n2/p。将这几项相加,总的时间大约是:
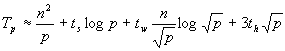
|