|
排序是计算机所需要经常完成的操作。由于排序后的数据常常比无序的数据更容易处理(比如查找的效率更高),所以很多算法要求数据是排序的。大数据量的排序在单个处理器上串行执行需要消耗大量的时间,这就提出了并行排序的需求。研究人员针对不同的并行计算机体系结构(PRAM、网格互连结构、超立方体结构等)对并行排序进行了研究。本章将介绍这些算法中比较典型的几个。
所谓排序,就是把给定的若干个元素按照某个大小比较标准排列起来,使得整个序列呈现升序(或降序)。形式化的定义为:设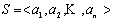 是一个任意序列,升序排序就是把S变为 是一个任意序列,升序排序就是把S变为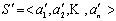 ,使得对于任意 ,使得对于任意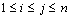 ,有 ,有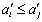 。 。
排序可以分为内部排序和外部排序。把要排序的数据全部装入内存的排序称为内部排序;而当数据量大到无法全部装入内存时,所采用的排序技术也有所不同,称为外部排序。本章着眼于内部排序。
常用的排序算法大多是基于比较(Comparison-based)的排序,已经证明,这类排序算法的最低时间复杂度是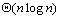 ,其中n是待排序的元素数目。另外一类排序不是基于比较的,而是根据元素的某些属性来进行排序,其最低时间复杂度是 ,其中n是待排序的元素数目。另外一类排序不是基于比较的,而是根据元素的某些属性来进行排序,其最低时间复杂度是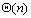 。本章把重点放在基于比较的并行排序。 。本章把重点放在基于比较的并行排序。
|