|
考虑下面的数据库表:
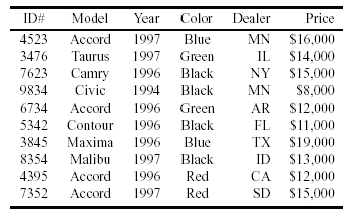
如果需要做如下的查询:
Select all
where ((MODEL="Accord" AND
YEAR="1996") AND
(COLOR="Green" OR COLOR="Black"));
这个查询寻找数据库中所有1996年产的绿色或黑色的Accord车的资料。在关系数据库中,这个查询通常需要创建几个中间表,一种可能的情形如下:一个表包含所有的Accord车数据,一个表包含所有1996款的车,一个表包含所有绿色车,一个表包含所有的黑色车。然后在这些表上进行Join操作,更详细的说,数据库将求出前两个表的交集,从而得到1996款的Accord车的表,同时,将求出后两个表的并,得到绿色或黑色的车的表,最后,用这两个表求交集,就得到了最后的数据。上面的操作可以用下面的图来形象的表示。图中的每个节点表示一个需要被计算的表(计算子任务),节点间的箭头给出了任务间的依赖关系。

在上面图中,只要所有必需的子任务已经完成,后续子任务就可以进行,因此,通常来说,很多的子任务都可以并行的执行。这种并行性表现为子任务的并行执行,因此被称为任务并行性。任务并行性比数据并行性要复杂一些(实际上,用任务并行性完全可以描述数据并行性的问题)。
|