|
9.5.3 基于转换的句法分析器
要求开发基于转换的句法分析器是有充分理由的。因为转换语法所表达的释义关系简化了后继阶段的处理。也许意义更深远的一个理由在于,如果计算语言学可以采用理论语言学家所使用的形式体系的话,那么他们已经取得的许多研究成果(包括某些专门的分析规则)便可以被直接应用。
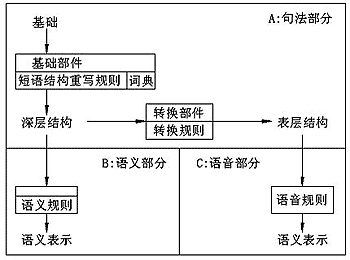
但是Chomsky的转换语法所要描写的是语言能力(linguistic competence),而不是言语行为(linguistic performance),它的转换规则是为基础所产生的深层结构设计的(见图9.9),用它来识别表层结构显然要比短语结构语法复杂得多。把图9.9所示的生成过颠倒过来,至少会有以下三个基本问题:
(1)对一个给定的句子生成一组句法树,它们应当包括转换语法要分配给这个句子的全部表层树;
(2)对于不属于基础的一棵给定的树,确定为生成这棵树可能使用的转换规则序;
(3)对转换规则逐条进行判定,如果它的结果是当前的这棵树,就不执行这条规则。
|
|
如果我们用最直接的方式来处理这些问题,那么我们可能不得不去尝试许多错误的路径。对于第一个问题,可以用一部上下文无关语法来产生转换语法可能分配给一个句子的全部表层树,其数量可能很大,这样的语法又叫做覆盖语法(covering grammar)。由于英语中大多数词都拥有不只一个词类,使这种"错误的"表层树的繁殖更其严重。对于后两个问题,可以设计出一组逆向的转换规则,但是由于不大可能事先唯一地判定产生一棵给定树的究竟是哪些转换,我们不得不去尝试许多逆向转换序而得不到一棵基础树。
由于这些困难,Matthews提出的那部最早的识别程序是正向工作的,即用转换语法来生成各式各样的表层树,直至有一棵表层树能同给定句子匹配。尽管在生成过程中也对给定句子进行某些检查,这部程序的效率仍非常之低,以至始终未能实现。
60年代中以A.Zwicky为代表的MITRE研究小组设计了一个基于转换的句法分析器,并取得了有限的成功。在A.Zwicky的系统中,转换生成语法的基础部件有275条规则,转换部件包含54条规则。他们为识别程序设计了一部拥有约550条产生式的上下文无关覆盖语法,用来产生表层树;另外还有134条逆向的转换规则。他们的识别过程由四个阶段组成:
(1)利用上下文无关覆盖语法,通过一个自底向上的句法分析器来分析输入句子;
(2)应用逆向转换规则;
(3)对步骤(1)和(2)所产生的每一棵候选的基础树,检查它是否事实上能够由基础部件所生成;
(4)对每棵基础树相通过步骤(3)的测试的转换规则序,应用正向转换规则以证实原先的句子确实可以生成。
第四步中的最后检查是必要的,因为覆盖语法有可能在逆向转换过程中导致输入句子同二个转纽发生虚假的匹配,而且逆向转换不见得包括了正向转换中的全部约束。事实上,覆盖语法产生了大量虚假的表层分析,这对后继的识别过程造成了很大的压力。
1965年的报导说,这部覆盖语核对一个12词长的句子产生了48种分析,每一种分析都要通过步骤(2)和(3),以便决定是否可被删除。因此整个识别过程非常慢,分析一个11词长的句子要用36分钟。
MITRE小组后来采用两种方法来提高系统的速度:
(1)"超树"(super-trees):即用于个单独的结构来表示几棵句法树。他们希望对这些超树应用逆向转换规则,以便能同时处理几种可能的表层结构;
(2)拒绝规则:在逆向转换过程(步骤(2))中应用这些拒绝规则来对树进行测试,以便在句法分析中尽可能早地淘汰某些虚假的树。在拒绝规则中收进了原先只出现在正向转换部件中的某些约束,从而可以删除步骤(2)中的某些树,而不让它们继续存在到步骤(4)。
据报导,这些措施,尤其是拒绝规则,对分析时间有重要影响,先前要36分钟才能分析的一个11词长的句子,改进后只需6分半钟。效率低这个缺点使得基于转换的句法分析器始终未能在自然语言理解系统中得到广泛的应用。