|
第二次迭代
步骤2:产生两个星
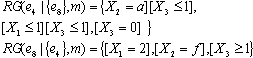
步骤3:从每个星中取一个复合,得到复合的所有组合。再经过不相交化过程处理,由LEF评价,从中选出最优聚类是
|
步骤4:这是第二次(最后一次)b迭代。
步骤5:复合[X1≤1][X3≤1]覆盖集合{e1,e2,e3,e4,e5},而复合[X1=2]覆盖集合{e6,e7,e8,e9,e10}。因为这个聚类比以前的聚类有改进(稀疏性更小),所以选中心事件e1和e8为新的根。
第三次迭代
这次迭代产生与第一次迭代相同的聚类。
步骤4:这次迭代没有改进。它是第一次p迭代。
步骤5:由于得到的聚类没有改进,所以选边缘事件e2和e6为新的根。
第四次迭代
步骤2和3:产生的最佳聚类是:
|
步骤4:这是第二次p迭代。如果得到的聚类优于以前最好的聚类,就安排另外两次p迭代。但这次稀疏性71不优于以前的53,所以满足结束条件。最优聚类是迭代2的结果
{[X1≤1][X3≤1] ,[Xl=2]}
5. 体系构成模块
体系构成模块利用聚类模块来确定分类体系。它实现两个循环,一个是迭代的,一个是递归的。迭代循环是对一系列K值重复执行聚类模块,以便确定能得到最优聚类的K值。这一循环的计算量是可接受的,因为在实用中最有意义的体系在每一层有相对较少的分支。
递归循环是在体系的每个节点使用迭代过程。第一步是对于表示初始事件集E的根执行该过程。确定E的聚类和合取描述。以后的步骤是对一些节点重复同样的操作,这些节点表示以前的步骤得到的聚类。体系自顶向下继续增大,直到不满足继续增大的准则。准则要求在体系每一层次上的分类及其描述间的复合优于以前的层次。
为了确定最优的K值,必须修改聚类准则,使之可以比较包括不同数目复合的聚类。该准则应该反映聚类和数据间的符合对K值的依赖性。当类型数K增加时,这种符合很可能增加。此外,增加K也增加了复杂性。一种准则考虑了上面的折衷,它要求乘积
总稀疏性×(K + b)
最小。其中b是实验确定的参数,它权衡稀疏性和类型数目K的相对影响。
6. 结论
上述的合取概念聚类可以确定对象的分类体系。每一类用一个合取命题描述,而且与同一父节点的其他类不相交,并使聚类准则最优。该方法与数值分类法的主要差别是,它把相似性测度的概念扩展为更一般的概念内聚。这种测度不仅考虑单个对象的特性,而且考虑对象之间的关系,以及它们与已知概念的关系。
这种方法的发展方向是:
(1) 希望确定新的,更有关的变量。
(2) 希望类型的描述不限于合取,还可以采用蕴涵和等价等联结词。
(3) 聚类准则应包含目标、目的和有关的努力。
(4) 分类结果不是树结构的体系,而是构成图结构的分类网。其中的链不仅表示父子节点关系,而且表示其他关系。
(5)对视觉信息聚类时,以各种标准几何形状为概念结构部件,如圆、三角、矩形等。而且允许非不相交的聚类。
(6)在需要考虑对象内部结构时(变量中包括对象各子部分特性间的关系时),需要更强的描述语言,如一阶谓词逻辑或其扩充。