|
4.聚类模块
CLUSTER/2的算法包括聚类模块和体系构成模块。这一节介绍聚类模块,下一节介绍体系构成模块。
(1)算法的全搜索方案
算法的目标可以描述为
给定:
被聚类的事件集合E
希望的类型数目K
聚类质量准则LEF
寻求:
事件集合的不相交聚类,使得给定的聚类质量准则LEF最优。
全搜索方案就是直接穷举搜索方案,其步骤为:
第一步:确定初始的根。从E中选K个事件为初始的根。可以任选或按一定准则选择。(这一步以后,再选根都是按一定准则。)
第二步:由根构成星。对每个根ei,令E0是其余根的集合。由减稀疏性过程构造简化星RG(ei|E0)。
第三步:构成最优聚类,即E的不相交覆盖。由K个星中各选择一个复合,这K个复合构成复合的集合。如果这K个复合不是互不相交的,则执行不相交化过程(NID过程),使复合不相交。
第四步:评价限定准则。对第一次迭代,保留得到的聚类。对以后的迭代,若新的聚类按LEF准则优于原存的聚类,就以新聚类代替原聚类。在预定数目的迭代不会产生更好的聚类时,算法结束。
第五步:选择新的根。对新产生的聚类中的每个复合(共K个复合),都有已观察事件集合,从中选新的根。从每个复合各选一个根。使用两种选根方法。一种方法是选择在中心的事件,该事件最接近复合的中心(由句法距离确定远近)。另一种方法是采用逆境原理。它选择远离中心的边缘事件。这有利于选用未作过根的事件。只要聚类在改进,就选择中心事件。如果聚类不再改善,就选择边缘事件。在选出K个新的根后,从第二步开始下一次迭代。
聚类模块的算法框图如图7.9所示。算法产生K个l-complex来描述各个聚类,并用LEF准则评价聚类。算法的结束条件是一个参数对(b,p)。其中b是算法必须进行的迭代次数。p是进行b次后的附加迭代次数。仅当一次迭代产生改善的聚类时,才进行附加的迭代。算法是基于动态聚类法(Diday和Simon,1976)。算法中计算量最大的部分是给定K个根后构成最优聚类(第三步)。
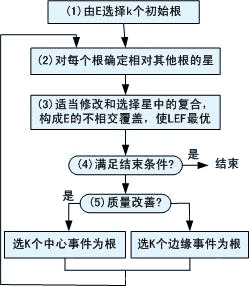 图7.9 聚类模块框图 |