|
6.5.1 一个扑克牌程序
Donald Waterman(1968)的程序可以玩"抽牌"扑克游戏。这是一种信息不完备的游戏,其中涉及心理学因素,例如一个对手是否容易受骗。不能用极大极小的前向搜索,因为不完全知道全局状态(即各人手中的牌)。他使用了近似的启发式规则。下面首先介绍系统中产生式规则的形式及其在执行环节中的使用,然后讨论获取和改善这些规则的方法。
1. 抽牌游戏程序的执行环节
这个游戏分五个阶段。第一阶段是发牌,发给每人五张牌。第二阶段是打赌,牌手轮流选择三种行动之一,或者放上大于对手赌注的赌注(RAISE行动),或者放上等于对手赌注的赌注(CALL行动),或者放弃这一手牌(DROP行动)。一次CALL或DROP行动结束这个阶段。第三阶段是换牌,每人有权选择用桌上抽出的新牌代替手中的三张牌。第四阶段也是打赌,与第二阶段相同。第五阶段比较各人手中牌(除DROP外),手中牌最好者胜这一局。
两个赌搏阶段是由可修改的产生式系统实现的,学习环节力求改善和学习这些产生式规则。产生式系统包括两类基本规则:解释规则 -- 用于计算游戏状态的特征,行动规则 -- 决定采用什么行动(RAISE,CALL或DROP)。
行动规则根据七个关键变量作出决策,这些变量构成动态的状态向量:
(VDHAND ,POT ,LASTBET ,BLUFFO,POTBET ,ORP, OSTYLE )
例如VDHAND测量程序手中的牌,POT是现在盘中的钱数,BLUFFO是对于欺骗能力的估计值。解释规则由可直接观测到的量计算这七个变量。例如为了计算BLUFFO值,要利用特征OBLUFFS(对方被发现有欺骗的次数)和OCORREL(对方手中牌与赌注的关系)等。计算出的七个变量都要化成符号值。例如当POT大于50时,令POT为BIGPOT。
行动规则根据这些符号值确定行动。例如一个行动规则是:
(SUREWIN ,BIGPOT ,POSITIVEBET,*,*,* ,*)
规则条件部分是状态向量的值(其中*可匹配任何值),结论部分一方面修改状态向量值,一方面采取行动(其中*表示不改)。上述规则的含义是:
如果:VDHAND = SUREWIN 且
POT = BIGPOT 且
LASTBET = POSITIVEBET
那么:令POT=POT=(2×LASTBET)
令LSATBET=0
并采取CALL
产生式规则的用法是,首先用解释规则分析当前状况,以便产生动态的状态向量;然后在固定排序的规则空间中搜索一条与状态向量匹配的规则,由此采取行动。
2. 学习产生规则的方法
Waterman 试图用程序来学习解释规则、行动规则和行动规则的排序。程序在与熟悉的对手玩扑克中学习。这时,学习环节分析执行环节的每一个决策,从中提取示教例子。每个示教正例就是示教规则,也就是作出正确决策的产生式规则。示教规则指导学习环节对产生式规则进行一般化或特殊化。
提取示教例子是很困难的。因为可以作为执行标准的信息太少。下棋一类游戏是确定性的,但扑克游戏是不确定的。为此,他使用了三种不同方法提取示教例子:建议采纳方法,自动示教方法和分析示教方法。
(1) 建议采纳方法
程序和著名牌手玩扑克。牌手对程序的每个决策作出评价。牌手或者回答(OK)表示同意程序的决策,或者提出建议,如
(CALL BECAUSE YOUR HAND IS FAIR ,THE POT IS LARGE ,ANDTHE LASTBET IS LARGE )
这种建议就是示教规则,它相当于:
(FAIR ,LARGE ,LARGE ,*,*,*,*)
对这种建议不必进行解释和处理,只要考虑怎样把它们放入知识库中。
(2) 自动示教方法
由一个玩牌程序作为学习程序的对手和提建议者。在玩牌中,由这个玩牌程序(相当于一个牌手)给学习程序提出建议。建议的形式和作用与(1)相同。
(3) 分析示教方法
这种方法不采纳建议。在一圈牌(每人一次)后,学习环节分析执行环节的作法,确定是否正确。它不依据外部提供的执行标准,而是使用扑克规则的谓词演算公理推出执行标准,然后提取示教规则,并用于修改产生式系统。修改过程是,首先找出作出错误决策的产生式规则,然后检查规则表中在该错误规则前后的规则。如果找不到这种规则,就把示教规则插入规则表中,放在错误规则前面。
分析示教方法的难点是奖惩分配问题。它必须处理两个奖惩分配问题。一个问题是确定一局牌的好坏。由于扑克游戏具有概率性,所以一局牌的失败不一定说明玩牌方法有错。另一个问题是确定哪一步决策不好。为此,学习环节用扑克规则的公理去评价每一步决策,由此得到对每一步的执行标准。系统共有四种行动:DROP ,CALL , BET HIGH 和BET LOW 。其中后两种是由RAISE划分的两种子行动。BET HIGH随机地选择10到20间的赌注,而BET LOW 随机地选择1到9间的赌注。
执行标准只确定示教规则的右边(行动部分),示教规则的左边(条件部分)由决策矩阵确定。决策矩阵包括四条抽象规则,分别对应四种行动。例如DROP行动的规则是
(CURRENT ,LARGE ,LARGE ,SMALL ,SMALL, CURRENT ,LARGE )
一旦确定适当的行动是DROP,就由决策矩阵取出这条规则,并把它作为示教规则。应该注意,决策矩阵中的规则是固定的,所以用它作为示教规则是不合适的。应该由程序发现和修改决策矩阵。目前系统还没有这种功能。
上面介绍了三种示教方法,下面说明如何用示教规则修改知识库。
(1) 修改解释规则
示教规则的左边(条件部分)与解释规则计算出的状态向量比较。LARGE匹配表示较大数值的符号值,SMALL匹配较小数值。如果有一个符号不匹配,就否定求出该符号的解释规则。例如,状态向量中的状态POT取值为P3,而P3是由下列规则得到:
IF POT>20 THEN POT =P3
而在分析牌局中的POT值是45。由于P3可能表示较小的值(如21),所以P3与LARGE不匹配。学习环境或者修改这条规则,以44代替20,或者产生下列新规则
IF POT>44 THEN POT =P4
这时POT取P4,P4与LARGE 匹配了。
解释规则修改以后,就以修正的状态向量与行动规则匹配,寻找作出错误决策的规则,并确定作出正确决策的规则。
(3) 修改行动规则
行动规则分两种:最近假设的和被接受的。最近假设的规则是最新加入知识库的规则。被接受的规则是程序认为几乎正确的规则。学习环节首先对被接受的规则作较小的修改。如果不解决问题,再对最近假设的规则作较大的修改。如是还不行,就把示教规则放入规则库,作为最近假设的规则。图6.16表示修改规则库的四步。图中R1,R2,… 表示库中规则的排序。
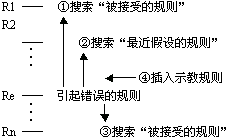 图6.16 修改行动规则的四步 |
第一步是由引起错误的规则Re向前搜索。寻找被接受的规则。检查它的条件部分是否可以一般化,以包含当前的状态向量(只考虑较小的一般化)。修改的目的是使这条规则可以在当前状态作正确决策,以至不再使用排在后面的错误规则Re。
如果第一步失败,则第二步从Re向前搜索,寻找最近假设的规则。希望对它的条件部分作较大的修改(一般化),目的与第一步相同。
如果第二步又失败,则第三步从Re 向后搜索,寻找被接受的规则,希望对这条规则一般化,以考虑当前状态,并对Re和它二者之间的规则特殊化,使之不考虑当前状态。这样,就可能不使用前面的错误规则,而使用后面的正确规则作出正确决策。
如果第三步也失败,则第四步把示教规则插入规则集,放在Re 以前,并标明为最近假设的规则。
把最近假设的规则变成被接受的规则应符合下列条件:规则的条件部分只剩下N个条件(N是程序给定的参数)。
3. 结果
Waterman用三种示教方法分别进行了测试。程序开始只有一条规则:"在任何情况下作任意的决策"。对前面两种示教方法,示教过程进行到程序在有五手牌的一局中未作一次错误决策(由专家判定)。对分析示教方法,示教过程进行到初始的"作任意决策"的规则只使用5%次。这时的结果对比如图6.17所示。图中最后一栏是对程序性能测试的结果。与牌手玩了两套各25手牌。第一套的25手牌是任意的抽出的。第二套的25手牌与第一套相同,只是程序和牌手的牌互换了。
程序总比对手胜少,故都是负值 图6.17种方法结果比较 |
结果表明,三种方法都有明显效果。自动示教比建议采纳更好,这可能是因为玩牌程序比牌手更稳定。分析示教的效果较差,这是因为它的公理集只提供了四种行动,而给前两种方法提供了八种行动。实际上,分析示教可能并不比前两种方法差。