的概率最大的词性链。
根据Bayes概率公式,有
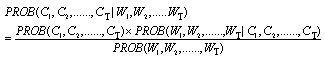
由于,句子(词串)出现的概率对于任何词性来说是不变的,因此上式的优化求解问题的讨论将转化为其分子部分因素的讨论,即,问题成为寻找C1,C2,……,CT使下式(1)最大。
PROB(C1,C2,...,CT)×PROB(W1,W2,...,WT|C1,C2,...,CT) (1)
式(1)中第一项可以改写为:
PROB(C1,...,CT)
= PROB(C1,...,CT-1)×PROB(CT|C1,...,CT-1)
= PROB(C1,...,CT-2)×PROB(CT-1|C1,...,CT-2)×PROB(CT|C1,...,CT-1)
= .......
= PROB(C1C2)×PROB(C3|C1C2)×...×PROB(CT|C1,...,CT-1)
= PROB(C1)×PROB(C2|C1)×PROB(C3|C2C1)×...×PROB(CT|C1,...,CT-1)
语言模型为n-gram模型时,我们考虑最简单的情况,使用二元模型bigram,那么:
PROB(C1,...,CT)
≌ PROB(C1|C0)×PROB(C2|C1)×...×PROB(CT|CT-1)
= ∏i=1,...,TPROB(Ci|Ci-1)
计算句子开始时,使用