3.递归过程BACKTRACK1(DATALIST)
在前面的回溯算法BACKTRACK中,设置了两个回溯点,一个是当遇到非法状态时回溯,一个是当试探了一个状态的所有子状态后,仍然找不到解时回溯。对于某些问题,可能会遇到这样的问题:一个是问题的某一个(或者某些)分支具有无穷个状态,算法可能会落入某一个"深渊",永远也回溯不回来,这样,就不能找到问题的解。另一个问题是,在某一个分支上具有环路,搜索会在这个环路中一直进行下去,同样也回溯不出来,从而找不到问题的解。如下图所示。
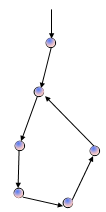
为了解决这两个问题,下面将给出回溯算法BACKTRACK1,该算法比前面的回溯算法增加了两个回溯点:一个是用一个常量BOUND来限制算法所能够搜索的最大深度,当前状态的深度达到了限制深度时,算法将进行回溯,从而可以避免落入"深渊";另一个是将过程的参数用从初始状态到当前状态的表来替代原来的当前状态,当新的状态产生时,查看是否已经在该表中出现过了,如果出现过,则表明有环路存在,算法将进行回溯,从而解决了环路问题。
从四皇后的例子看出搜索深度有限,仅有4层,而且不可能出现重复状态的问题,因此BACKTRACK过程完全适用。对于八数码问题则不然,必须设置深度范围限制及防止出现重复状态引起的死循环这两个回溯点,改进后的算法如下:
递归过程BACKTRACK1(DATALIST)
⑴DATA:=FIRST(DATALIST);设置DATA为当前状态
⑵IF MEMBER(DATA,TAIL(DATALIST)),RETURN FAIL;TAIL是取尾操作,表示取表DATALIST中除了第一个元素以外的所有元素。如果DATA在TAIL(DATALIST)中存在,则表示有环路出现,过程返回FAIL,必须回溯。
⑶IF TERM(DATA),RETURN NIL;TERM取真即找到目标,则过程返回空表NIL。
⑷IF DEADEND(DATA),RETURN FAIL;DEADEND取真,即该状态不合法,则过程返回FAIL,必须回溯。
⑸IF LENGTH(DATALIST)>BOUND,RETURN FAIL;LENGTH计算DATALIST的长度,即搜索的深度,当搜索深度大于给定值BOUND时,则过程返回FAIL,必须回溯。
⑹RULES:=APPRULES(DATA);APPRULES计算DATA的可应用规则集,依某种原则(任意排列或按启发式准则排列)排列后赋给RULES。
⑺LOOP:IF NULL(RULES),RETURN FAIL;NULL取真,即规则用完未找到目标,过程返回FAIL,必须回溯。
⑻R:=FIRST(RULES);取头条可应用规则。
⑼RULES:=TAIL(RULES);删去头条规则,减少可应用规则表的长度。
⑽RDATA:=GEN(R,DATA);调用规则R作用于当前状态,生成新状态。
⑾RDATALIST:=CONS(RDATA,DATALIST);将新状态加入到表DATALIST中。
⑿PATH:=BACKTRACK1(RDATALIST);递归调用本过程。
⒀IF PATH=FAIL,GO LO0P;当PATH=FAIL时,递归调用失败,则转移调用另一规则进行测试。
⒁RETURN CONS(R,PATH);过程返回解路径规则表(或局部解路径子表)。
在过程BACKTRACK1中,形参DATALIST是从初始状态到当前状态的逆序表,即初始状态排在表的最后,而当前状态排在表的最前面。返回值同前面的算法一样,是以规则序列表示的路径表(当求解成功时),或者是FAIL(当求解失败时)。
这个算法与前者的差别是递归过程自变量是状态的链表,取返回到初始状态路径上所有状态组成的一张表,而DATA则是当前的一个状态。此外在第2、5步增设了两个回溯点以检验是否重访已出现过的状态和限定搜索深度范围,这分别由谓词MEMBER和>,函数LENGTH,常量BOUND实现。
这里介绍的回溯搜索策略,在有些书中称为"深度优先"搜索,而在本书中"深度优先"搜索有另外的含义,具体请见"深度优先"搜索一节。
推广的回溯算法可应用于一般问题的求解,但这两个算法只描述了回溯一层的情况,即第n层递归调用失败,则控制退回到(n-1)层继续搜索。实际上往往造成深层搜索失败在于浅层原因引起,因此也可以利用启发信息,分析失败的原因,再回溯到合适的层次上,这就是多层回溯策略的思想,目前已有一些系统使用了这种策略。